Affinity Propagation
1. Before Starting
If you are not familiar with Affinity Propagation, please see Wikipedia or the original paper “Clustering by Passing Messages Between Data Points(2007)” by Brendan J. Frey, Delbert Dueck.
2. Notions
- Similarity \(s(i,k)\): the similarity between point \(k\) and point \(i\). It could be the negative Euclidean distance as follower:
- Preferences \(s(k, k)\): data points with larger values of \(s(k, k)\) are more likely to be chosen as exemplars. \(s(k,k)\) could be the median of the similarities(resulting in a moderate of clusters) or their minimum(resulting in a small number of clusters). In this article, we set each \(s(k, k)\) to the median as default.
- Responsibility \(r(i, k), i \rightarrow k\), send from point \(i\) to point \(k\), reflects the accumulated evidence that how well-suited point \(k\) is to serve as the exemplar for point \(i\). For candidate \(k\), it only needs to compete with the best other candidate.
- Self-responsibility \(r(k, k)\), reflects accumulated evidence that point \(k\) is an exemplar. \(r(k,k) \leq 0\) means it is better for point \(k\) not to be an exemplar.
- Availability \(a(i, k), k \rightarrow i\), send from point \(k\) to point \(i\), reflects the accumulated evidence for how appropriate it would be for point \(i\) to choose point \(k\) as its exemplar.
- Self-availability \(a(k, k)\), reflects accumulated evidence that point \(k\) is an exemplar, based on the positive responsibilities sent to \(k\) from other points.
- Criterion \(c(i, k)\), is the combination of the two messages, used to identify exemplars.
- Damping factor \(\lambda\), used to smooth the message-updating procedure. At each iteration step \(t+1(t \geq 0)\),
- Best exemplar \(k^*\), for each point \(i\), the exemplar will be
3. How To Understand?
For \(r(i, k)\), we can roughly see it as the indicator measuring how appropriate for point \(i\) to choose candidate \(k\) as its exemplar compared with other candidates. Larger similarity, other candidate’s smaller availability, and other candidate’s smaller responsibility will bring on a larger responsibility for candidate \(k\).
As for \(a(i, k)\), we can roughly see it as the candidate \(k\) promotes itself to point \(i\) using the sum of the self-responsibility and the positive responsibilities received from other points. Since a particular candidate doesn’t need to serve the whole data set, it doesn’t matter how bad for a candidate be the exemplar for some points. Therefore, AP only calculates the positive responsibilities. And also, to limit the really large responsibilities from some points or even a single point, AP sets an upper limits(which is 0) to \(a(i, k)\), makes \(a(i, k) \leq 0\). What’s more, a negative \(a(i, k)\) can insure a candidate with largest similarity receives a positive responsibility.
For damping factor \(\lambda\), it is used to avoid numerical oscillations. It is import to damping the responsibility matrix \(R\) first, then using the damped \(R\) to update the availability matrix \(A\).
4. When To Converge And How To Find Exemplars?
It will be converged when the exemplars stay constant for some number of iteration, or the changes in the messages fall below a threshold. In this article, we use the first one. When is converged, AP use the criterion matrix \(C\) to find the exemplars. In each row \(i\) of the criterion matrix \(C\), the point with the max value(e.g. point \(k\)) is either the exemplar for point i(if k != i) or is the exemplar(if k == i).
5. A Numpy Python Implementation
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
from sklearn.metrics.pairwise import euclidean_distances
import copy
# 1. import data
X, y = make_blobs(n_samples=100)
X.shape, y.shape
# 2. calculate Similarity Matrix, equation (1), (2)
def cal_Similarity(X, preference):
S = -euclidean_distances(X, X)
if preference == 'min':
preference = np.min(S)
else:
preference = np.median(S)
np.fill_diagonal(S, preference)
return S
# 3. calculate Responsity Matrix, equation (3)
# 3.1 find max{a_ik'+s_ik'}, k' != k
def cal_largest_criterion_except_k(S, A):
n = S.shape[0]
row_index = np.arange(n)
C = A + S
max_index_each_row = np.argmax(C, axis=1)
C_copy = copy.deepcopy(C)
# replace the max value to -np.inf to find the second max value
C_copy[row_index, max_index_each_row] = -np.inf
second_max_index_each_row = np.argmax(C_copy, axis=1)
# get the max value for each row
max_value_each_row = C[row_index, max_index_each_row]
# get the second max value for each row
second_max_value_each_row = C[row_index, second_max_index_each_row]
R_to_substract = np.zeros(shape=(n, n))
R_to_substract[row_index] = max_value_each_row.reshape(-1, 1)
R_to_substract[row_index, max_index_each_row] = second_max_value_each_row
return R_to_substract
def cal_Responsity(S, A):
R_to_substract = cal_largest_criterion_except_k(S, A)
return S - R_to_substract
# 4. cal Availability Matrix A, equation (5),(6)
def cal_Availability(S, R):
n = S.shape[0]
R_dia = R.diagonal()
R_ramp = np.maximum(R, 0)
R_ramp_dia = R_ramp.diagonal()
R_ramp_sum = np.sum(R_ramp, axis=0)
# a(i, k) = min{0, R(k, k) + R_ramp_sum[k] - R_ramp(i, k) - R_ramp(k, k)}
A = -R_ramp - R_ramp_dia + R_dia + R_ramp_sum
A = np.minimum(A, 0)
# fill the diagonal with a(k, k) = sum_{i'!=k} max{0, r(i', k)}
R_ramp_copy = copy.deepcopy(R_ramp)
# fill diagonal with 0 to exculde
np.fill_diagonal(R_ramp_copy, 0)
A_dia = np.sum(R_ramp_copy, axis=0)
np.fill_diagonal(A, A_dia)
return A
# 5. and 6. Find exemplars and labels
# for each the max value of c(i, k)
# either identifies point i as an exemplar if k = i,
# or identifies the data point that is the exemplar for point i
# 5. find exemplars
# also, exemplars equal to the points whoese diagonal value > 0, that is
# exemplars = row_index[C.diagonal() > 0]
def cal_exemplars(C):
n = C.shape[0]
row_index = np.arange(n)
max_index_each_row = np.argmax(C, axis=1)
exemplars = row_index[row_index == max_index_each_row]
return exemplars
# 6. find labels
def cal_labels(C_res, exemplars_res):
n = C_res.shape[0]
row_index = np.arange(n)
max_index_each_row = np.argmax(C_res, axis=1)
k = exemplars_res.shape[0]
labels = np.zeros(shape=(n, ))
for i in range(k):
exemplar = exemplars_res[i]
cluster = row_index[max_index_each_row == exemplar]
labels[cluster] = i
return labels
# 7. Put together
# import note: use the damped R to update A!!!
# the paper didn't mention that
def ap(X, preference, damping, max_iter, stop_iter):
n = X.shape[0]
# 1. calculate Similarity
S = cal_Similarity(X, preference)
# 2. init Availabiliy, Responsibility to zeros
A = np.zeros(shape=(n, n))
R = np.zeros(shape=(n,n))
C = R + A
exemplars = cal_exemplars(C)
accum_count = 0
left_iter = max_iter
while left_iter > 0:
# 3. calculate Responsity, Availability
R_updated = cal_Responsity(S, A)
# Damping First! Very Important! Or May Not Converge
R = damping*R + (1-damping)*R_updated
A_updated = cal_Availability(S, R)
A = damping*A + (1-damping)*A_updated
C_updated = R + A
exemplars_updated = cal_exemplars(C_updated)
num = exemplars.shape[0]
num_updated = exemplars_updated.shape[0]
if num > 0 and (num == num_updated) and np.allclose(exemplars, exemplars_updated):
accum_count += 1
if accum_count == stop_iter:
labels = cal_labels(C_updated, exemplars_updated)
print('Converge at iter', max_iter - left_iter)
return labels, exemplars_updated
exemplars = exemplars_updated
C = C_updated
left_iter -= 1
print('Not converge.')
return np.array([-1]*n), []
# 8. Compare and Show Results
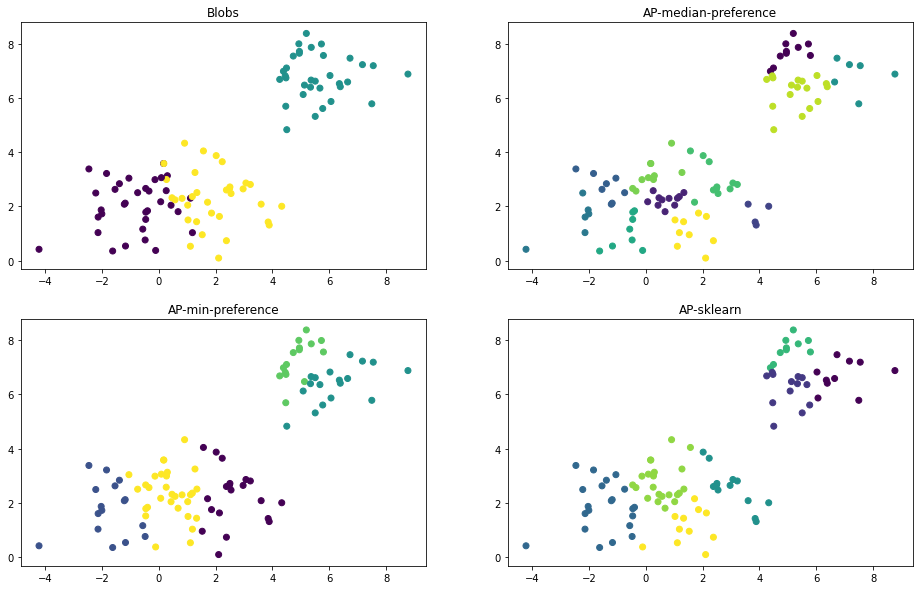
# 8.1 with median preference
labels_median, cluster_centers_median = ap(X, 'median', 0.5, 100, 20)
# 8.2 with min preference
labels_min, cluster_centers_min = ap(X, 'min', 0.5, 100, 20)
# 8.3 Sklearn
from sklearn.cluster import AffinityPropagation
ap_sklearn = AffinityPropagation(random_state=42).fit(X)
labels_sklearn = ap_sklearn.labels_
cluster_centers_sklearn = ap_sklearn.cluster_centers_indices_
# 8.4 show results
def plot_scatter(ax, X, labels, title):
ax.scatter(X[:, 0], X[:, 1], c=labels)
ax.set_title(title)
fig, axes = plt.subplots(2, 2, figsize=(16, 10))
plot_scatter(axes[0, 0], X, y, 'Blobs')
plot_scatter(axes[0, 1], X, labels_median, 'AP-median-preference')
plot_scatter(axes[1, 0], X, labels_min, 'AP-min-preference')
plot_scatter(axes[1, 1], X, labels_sklearn, 'AP-sklearn')
6. References
- Brendan J. Frey, Delbert Dueck(2007). “Clustering by Passing Messages Between Data Points”.